


LLM architectures, Open LLMs and more


Welcome to the fifth edition of our newsletter The Token! In this episode we take a brief look at emerging LLM architectures from Andreesen Horowitz blog, two new open source LLMs and the current state of open source LLMs. We also dive into a discrepancy in the open LLM leaderboard that showed Falcon 🦅 to be superior to Llama 🦙 and close with a look at a new research paper that trains a rather small LLM with an equally small dataset to achieve competitive performance with much bigger models.
As ever, let us know what you think, and if you find yourself in need of help with an NLP problem, get in touch at hi@mantisnlp.com.
✍️ Emergent Architectures for LLM applications
Andreesen Horowitz, one of the most known venture capital firms in the valley, wrote about some common architectural choices that have been emerged in the applied LLM space. They observe that most startups start with in context learning vs fine tuning an LLM when building their product. They break down and discuss three stages of in context learning. Let's see them one by one.
1️⃣ Data preprocessing
This is the step where data is being collected and split into smaller chunks, transformed into a numerical representation (embeddings) and stored into a vector database. Most startups seem to be using OpenAI embeddings and in particular text-embedding-ada-002. In terms of vector databases the most popular choice seems to be Pinecone with a lot of alternatives like Weaviate and Qdrant.
2️⃣ Prompt construction
This is the stage where the relevant data is retrieved and interleaved into the prompt. This is the step where tools like LangChain and LlamaIndex add the most value. This is because they provide useful abstraction for complex prompt strategies like chaining, keeping memory and more.
3️⃣ Prompt execution
In that step OpenAI is the clear leader with the majority using either GPT4 or GPT3.5 depending on the speed 🏎 accuracy 🚀 cost 💵 requirements. Even though there a gap to even GPT3.5, it seems to be closing, especially with models such as Llama but also commercially viable options like Falcon and the Mosaic models.
🔗 Read more here https://a16z.com/2023/06/20/emerging-architectures-for-llm-applications/

Llama 🦙 or Falcon 🦅 ?
🤔 Which model is better 🦙 Llama 65B or 🦅 Falcon 40B? The short answer is Llama but the nuanced answer is it depends.
If you have been following the news around open source Large Language Models closely you might have noticed the following inconsistency that has sparked some discussion. Even though Falcon and Llama are trained on relatively similar data and their architecture is similar to a large extent, for some reason the smaller 40B Falcon model was able to outperform the larger Llama 65B according to the open source LLM benchmark maintained from huggingface 🤗
On closer inspection the numbers reported for Llama are different from the paper which is why this sparked some conversation as to what that is. Well huggingface 🤗 decided to do a deep dive into the reasons and publish an explainer. As it turns out, each evaluation library was calculating metrics a bit differently and in particular the one used from huggingface, which came from Eleutherai, the company behind GPTJ and Pythia, seemed to favorite Falcon unintentionally, something they have now addressed.
This highlights the importance of having open source reproducible benchmarks to evaluate models. The Open LLM leaderboard is one such effort from huggingface 🤗 The only way we can interrogate and trust the results is to have more of these discussions.
🔗 Read more here https://huggingface.co/blog/evaluating-mmlu-leaderboard

OpenLlama 13b 🦙 and MPT 30B Ⓜ️
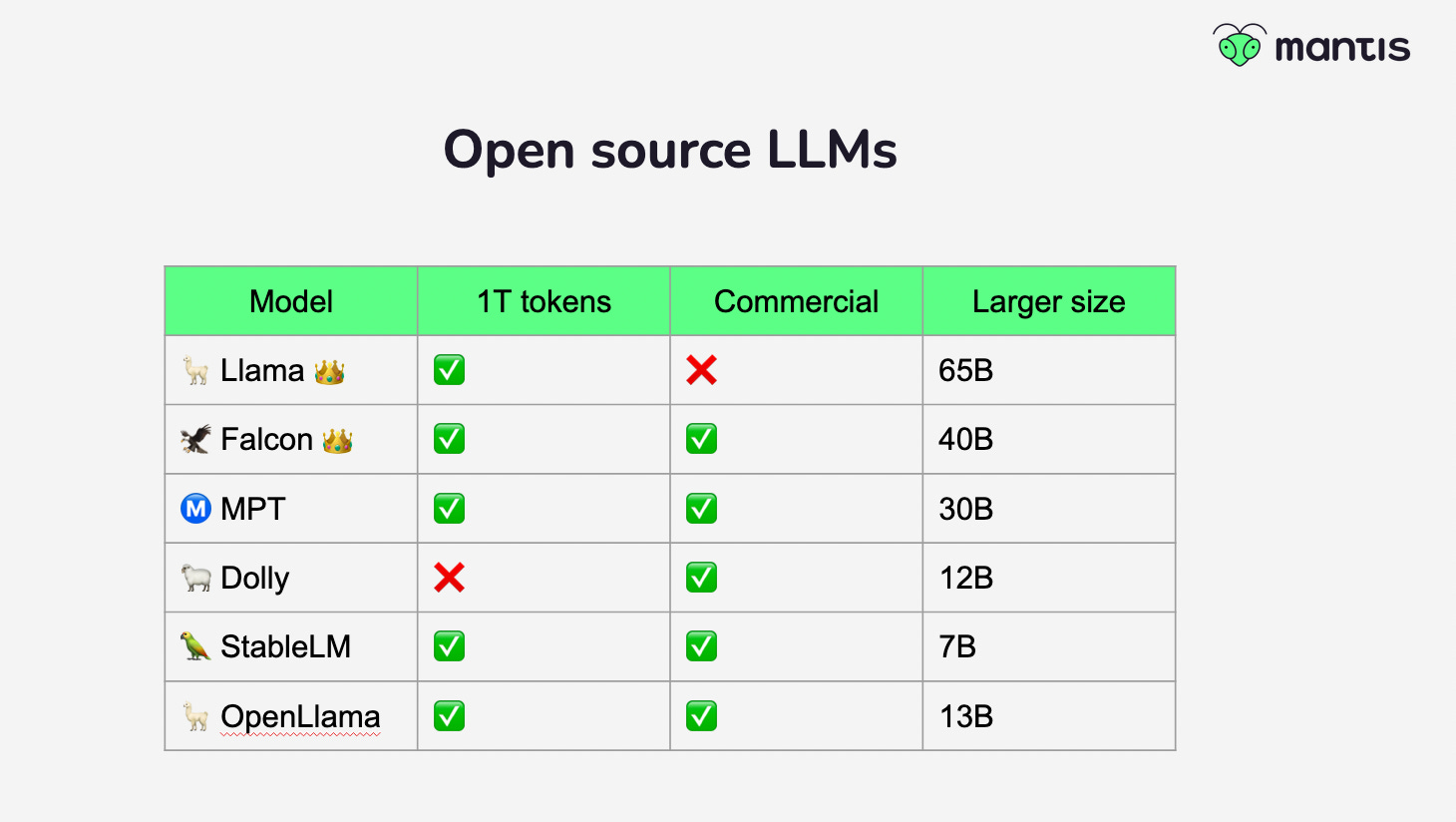
✨ In the last two weeks, two more open source Large Language Models were released, OpenLlama 13b and MPT 30B. At this point you might have lost track as to which model is the best to use understandably. The short answer is Llama 🦙 is still the best open source large language model but it does not come with a commercial license while Falcon 🦅 is the best commercial alternative.
One thing to keep an eye on when reading about a new open source large language model is the number of tokens it was trained on. The most performant models at this point are trained with around 1T tokens. This applies to Llama 🦙, Falcon 🦅, MPT Ⓜ️ and StableLM 🦜 but not models like Pythia, Cerebras or Dolly.
Assuming the model was trained on 1T tokens or more, then parameter size is a good indicator of performance. The most common sizes that LLMs come at are around 7b, 13b, 30B and 60B. At the moment Llama comes at all sizes while Falcon and MPT provide a model at the 30B range and StableLM stops at 7B. All have announced plans to train models at all these sizes so we should see more models released very soon.
There is an ongoing debate as to whether it is possible to replicate the performance of a larger model using a smaller one. Alpaca and friends first claimed this was possible with subsequent work (false promise of imitating proprietary llms) turning this around and then orca showing that its possible again by using chain of thoughts explanations to learn from. It is worth keeping in mind that most probably some form of compressing or distilling the knowledge from a large model is possible with the exact mechanism to be defined but this still means you need a teacher model and that its legal to do so ⚖️
🧪 Textbooks are all you need
Phi, a 1.3B "large" language model, outperforms StarCoder 💫, a 15.5B model, on code completion 🔥
The secret sauce behind it is data quality ✨ The author construct a dataset of less than 7B tokens, compared to 1T that StarCoder and others models use, that is carefully curated to contain textbook like examples which are self contained and well documented. They prompt GPT4 to select examples that are of high educational value and they also use GPT3.5 to create textbook examples and exercises. They then use the filtered and synthetic textbook examples to train a base model and the exercises to fine tune that model.
This work further demonstrates that a small amount of high quality data can be equivalent to orders of magnitude more data that is noisy and unfiltered. It means companies need to invest in the data quality as much as in training those models. It also means that training state of the art language models is becoming more accessible 🚀
🔗 Read more here https://arxiv.org/pdf/2306.11644.pdf
